

Reliability is important in research because it helps to ensure that the results are accurate and consistent. There are several different types of reliability, each of which is important in its own way.

The reliability of a measure reflects how well it is free of bias (error) and so assures consistent measurement throughout time and across the many components in the instrument. In other words, a measure’s reliability is an indication of the stability and consistency with which the instrument assesses the idea and aids in determining the “goodness” of a measure.

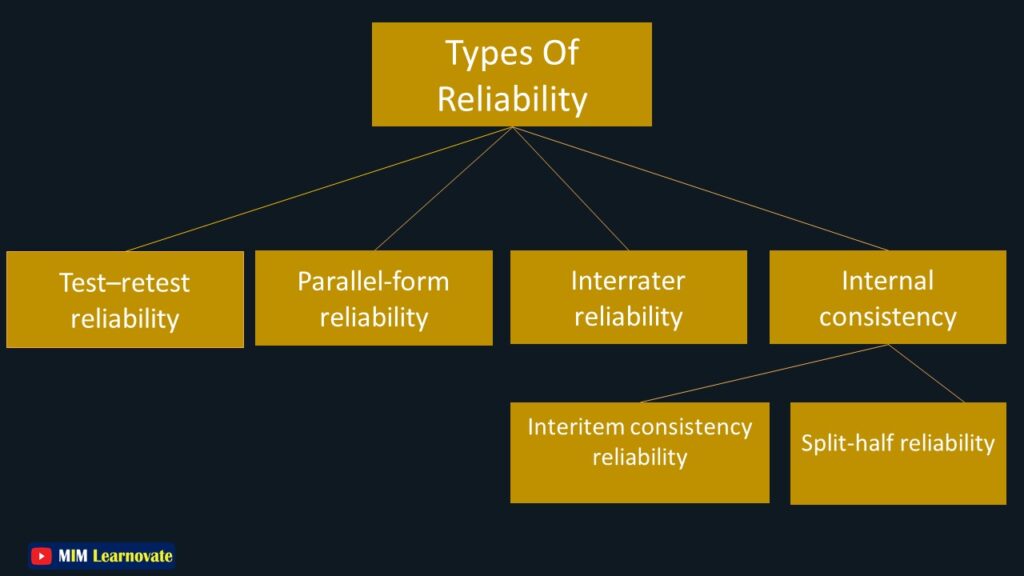
Types of Reliability in Research
There are four types of reliability in research.
- Internal consistency
- Test–retest reliability
- Parallel-form reliability
- Inter-Rater reliability
Let’s have look at types of reliability in research and get free Pdf to download at the end of this article.
Internal Consistency
Internal consistency is a measure of how well a test or assessment tool predicts the same results when administered more than once to the same group of people.
✔ A test with high internal consistency will produce similar results each time it is given.
✔ A test with low internal consistency will produce widely varying results.
Internal consistency in research is the idea that all the data collected during a study should be consistent with one another. This means that if there are any discrepancies between the data, they should be able to be explained by the researcher. Internal consistency in research refers to the reliability of results across different measures or items.
Internal consistency is important because
- it allows for replication of results and also helps to ensure that the data collected is valid and reliable.
- it allows researchers to have confidence in the results of their studies.
If a study find that a certain treatment is effective, but the study has low internal consistency, it is difficult to know whether the treatment actually worked or if the results were simply due to chance.

Example
If a study found that people who reported higher levels of stress also had higher levels of anxiety, we would expect to see a similar relationship between stress and anxiety in other samples of people. If the relationship between stress and anxiety is consistent across different measures and samples, we can be more confident that it is a real phenomenon.
Types of Internal Consistency
The interitem consistency reliability and split-half reliability tests can be used to assess internal consistency.
Interitem Consistency Reliability
The interitem consistency reliability test assesses the consistency of respondents’ responses to all items in a measure. Items will be correlated with one another to the extent that they represent independent measures of the same notion.

Interitem Consistency Reliability Test
The most often used interitem consistency reliability test:
✔ Cronbach’s alpha coefficient is used for multipoint-scaled questions (Cronbach, 1946)
✔ Kuder-Richardson formulae are used for dichotomous items. (Kuder & Richardson, 1937)

Split-half Reliability Test
Split-half reliability illustrates the correlations between the two halves of an instrument. The estimations will differ based on how the measure’s items are split into two halves.

How to Measure Internal Consistency?
There are several ways to measure internal consistency, but one of the most common is Cronbach’s alpha. This statistic measures the correlation between different items on a test or assessment tool.
Test-retest
Test-retest reliability is a measure of the stability of a test over time. It is the consistency of your results when you take the test more than once. Test-retest reliability is the degree to which a measure is consistent between two administrations of the test.

The test-retest reliability is the reliability coefficient achieved by repeating the same measure on a second occasion.
✔ A high test-retest reliability means that your results are similar each time you take the test
✔ A low test-retest reliability means that your results may vary from one occasion to the next.
When conducting research, test-retest is an important method to consider.
- allows for researchers to see how well participants retain information and how their scores may have changed over time.
This is when the same participants are tested at two different times, with the second testing session occurring after a period of time has passed. This method is reliable because it eliminates outside factors that could affect the results of the test, such as nerves or stress.
Example:
A questionnaire containing some items intended to measure a concept is administered to a group of respondents. After several weeks to six months, same questionnaire is administered again to the same group of respondents. The correlation between the scores obtained at the two different times from the same group of respondents is referred to as the test-retest coefficient. ✔ The greater it is, the better the test-retest reliability and, as a result, the measure’s stability over time.

If a student gets a score of 80 on a math test one day and then gets a score of 82 on the same math test given to her again on another day, we would say that the test has good test-retest reliability. The higher the score, the more reliable the test.
Test-retest as a Research Method
There are several things to keep in mind when using test-retest as a research method.
First, it is important to have a clear idea of what you want to measure.
Second, you must be aware of the potential for practice effects, which is when participants’ scores improve simply because they have taken the test before and know what to expect.
Finally, it is crucial to use the same form of the test during both testing sessions in order to ensure that results are comparable.
Test-retest Reliability Estimate
There are a few things to keep in mind when using a test-retest reliability estimate.
First, it is important to use the same measure each time. This means that you should use the same questions or tasks each time.
Second, you should administer the test at least two times. This will help to ensure that you have enough data to compare.
Finally, it is important to consider the time frame between administering the tests. You want to make sure that there is enough time for people to have forgotten their responses from the first test.
When to Use Test-retest?
- can be used for anything from academic testing to intelligence testing
- way to measure how well someone does on a task when they are given the same conditions twice.
- important tool for measuring progress and improvement.
- used in schools to track student achievement, in businesses to measure employee training progress, and in research to compare results over time.
Parallel forms
When responses on two comparable sets of measurements tapped the same construct are highly correlated, this is referred to as parallel-form reliability.

Parallel forms are two or more versions of a test that measure the same construct. The purpose of using parallel forms is to increase the reliability of the assessment by providing alternate versions of the test. This is especially important when the test is being used for high-stakes purposes, such as making decisions about promotion or placement.
Parallel forms are two or more versions of a test or questionnaire that are identical in terms of content and format. This means that the only difference between the forms is the order of the items.
There are several advantages to using parallel forms.
- it reduces the chance that a person will get a “lucky” score on one version of the test and not on another.
- can help reduce testing bias by making it more difficult for people to figure out what types of answers are being rewarded.
- having multiple versions of a test can help keep people from becoming too familiar with the format and content of the assessment.
- helps to reduce bias and error in research. It also allows researchers to compare results across different groups of people.
Example
If a student were to take Form A of a particular test and then take Form B of the same test, their scores would be comparable. The main purpose of having parallel forms is to ensure that students’ scores are not impacted by which form they receive.
If a researcher wanted to compare the results of a test administered to two different groups of people, they could use parallel forms. This would allow them to see if there were any significant differences between the groups.
Inter-Rater
In order to ensure the accuracy of measurements and data, it is important that different observers or raters agree on what they are seeing. This concept is called Inter-Rater reliability, and it is a critical element in many fields, from psychological testing to education.

The degree of agreement between different people witnessing or assessing the same object is measured by Inter-Rater reliability also known as interobserver reliability. It is used when researchers collect data by assigning ratings, scores, or categories to one or more variables.
Ways to measure Inter-Rater Reliability
There are a few different ways to measure interrater reliability.
- Percent agreement
- Cohen’s kappa
Percent agreement
The most common is percent agreement, which simply looks at how often two or more observers agree on a particular rating.
Cohen’s kappa
Another option is Cohen’s kappa, which takes into account both agreements and disagreements.
No matter which method you use, it is important to establish Inter-Rater reliability before you can trust your data. Without it, you run the risk of making inaccurate conclusions based on faulty information.
Testing for Inter-Rater reliability
There are a few things to consider when testing for Inter-Rater reliability.
1️⃣The first is the type of agreement that you are looking for.
There are two types of agreement, chance and systematic.
Chance agreement
Chance agreement is when there is no relationship between the two ratings.
Systematic agreement
Systematic agreement is when there is a relationship between the two ratings.
2️⃣ The second thing to consider is the level of agreement you are looking for.
There are four levels of agreement: perfect, good, fair, and poor.
Perfect agreement
Perfect agreement means that the two raters always agree.
Good agreement
Good agreement means that the two raters agree most of the time.
Fair agreement
Fair agreement means that the two raters agree some of the time. Poor agreement means that the two raters rarely agree.
3️⃣ The third thing to consider is how many items you will be rating.
When two or more people independently rate something, it’s important that their ratings are reliable, or in agreement.
✔ When reliability is high, it means that different raters will tend to agree with each other on the rating they give.
Example
one common method is to calculate the percentage of times that raters agree with each other. For example, if two raters agree 80% of the time, we would say that the reliability of their ratings is 80.
Factors influence Inter-Rater reliability
There are a number of factors that can influence interrater reliability,
- how well defined the task is that’s being rated
- how much training the raters have had
- whether the raters are using a standardized rating scale.
FAQs About Reliability
How to improve Reliability?
Two methods exist for improving reliability:
✔ By standardizing the conditions of measurement, we must ensure that external sources of variation such as boredom, exhaustion, and so on are minimized to the greatest extent possible. This will increase the element of stability.
✔ By utilizing well developed measurement instructions with no variation from group to group, conducting the research with well-trained and motivated individuals, and and by extending the sample of items used. This will increase the aspect of equivalency.
Which type of reliability is appropriate for your research?
| Methodology | Types of Reliability Used |
| Using a multi-item test in which each item is designed to measure the same variable. | Internal consistency |
| Multiple researchers make observations or provide scores to the same topic. | Interrater |
| Measuring a property that is expected to remain constant across time. | Test-retest |
| Two distinct tests are used to measure the same item. | Parallel forms |

Other articles
Please read through some of our other articles with examples and explanations if you’d like to learn more about research methodology.
Statistics
Methodology
- Research Methods
- Quantitative Research
- Qualitative Research
- Case Study Research
- Survey Research
- Conclusive Research
- Descriptive Research
- Cross-Sectional Research
- Theoretical Framework
- Conceptual Framework
- Triangulation
- Grounded Theory
- Quasi-Experimental Design
- Mixed Method
- Correlational Research
- Randomized Controlled Trial
- Stratified Sampling
- Ethnography
- Ghost Authorship
- Secondary Data Collection
- Primary Data Collection
- Ex-Post-Facto
Research
- Table of Contents
- Dissertation Topic
- Synopsis
- Thesis Statement
- Research Proposal
- Research Questions
- Research Problem
- Research Gap
- Types of Research Gaps
- Variables
- Operationalization of Variables
- Literature Review
- Research Hypothesis
- Questionnaire
- Abstract
- Validity
- Reliability
- Measurement of Scale
- Sampling Techniques
- Acknowledgements
1 Comment
Hello just wanted to give you a quick heads up and let you know a few of the images aren’t loading properly. I’m not sure why but I think its a linking issue. I’ve tried it in two different web browsers and both show the same outcome.