

In this article, you will learn what is distributed system, its pros and con and also you will learn, how to Build a distributed system?
With companies expecting software solutions to manage ever-increasing amounts of requests and network bandwidth usage, apps must be primed for scale. It’s time to develop a distributed system if you require quick delivery of resilient, resource-conserving systems.
To successfully construct a heterogeneous, secure, fault-tolerant, and efficient distributed system, you must be conscientious and have some level of experience.
According to research conducted by Industry ARC, “The Distributed Cloud Market is forecast to reach $3.9 billion by 2025, growing at a CAGR of 24.1% during the forecast period from 2020-2025.”
Emergence of distributed computer system
Before we get started on building a distributed computer system, it’s important to understand its historical context. Prior to the development of distributed computing, mainframe computers predominated, with IBM Mainframe being the most well-known.
Up until the middle of the 1990s, mainframes were the most significant process of large amount of data. These data processing tasks were done centrally, and each peripheral device was under the supervision of the central processor.
IBM Mainframe increased its market share by providing valuable services, such as:
- Large numbers of concurrent users and application programs could be supported by these mainframe computers with ease.
- It had remarkable security, compatibility, reliability, serviceability, availability.
- Large, distributed databases were handled effectively by IBM Mainframe computers.
- It carried out extensive transaction processing.
The Need for Distributed Computing Beyond Mainframes
Although mainframes had numerous benefits, they also had certain disadvantages, such as
- Small firms couldn’t afford these computers, however major organizations could because of their high cost.
- Specialized skill was necessary for running, maintaining, and troubleshooting mainframe computers.
- Organizations using mainframe computers had to make financial investments in data centers with the necessary specialized software and hardware.
As personal computers (PCs) became more widespread, more firms were ready to make computer-related investments. Naturally, this led to more users being online at once, and computing systems had to be able to handle them. It was necessary to find a new computing paradigm.
What is distributed computing?
Distributed computing is a type of computing that breaks down a user requirement into smaller chunks. The computing system then distributes these duties among many networked machines.
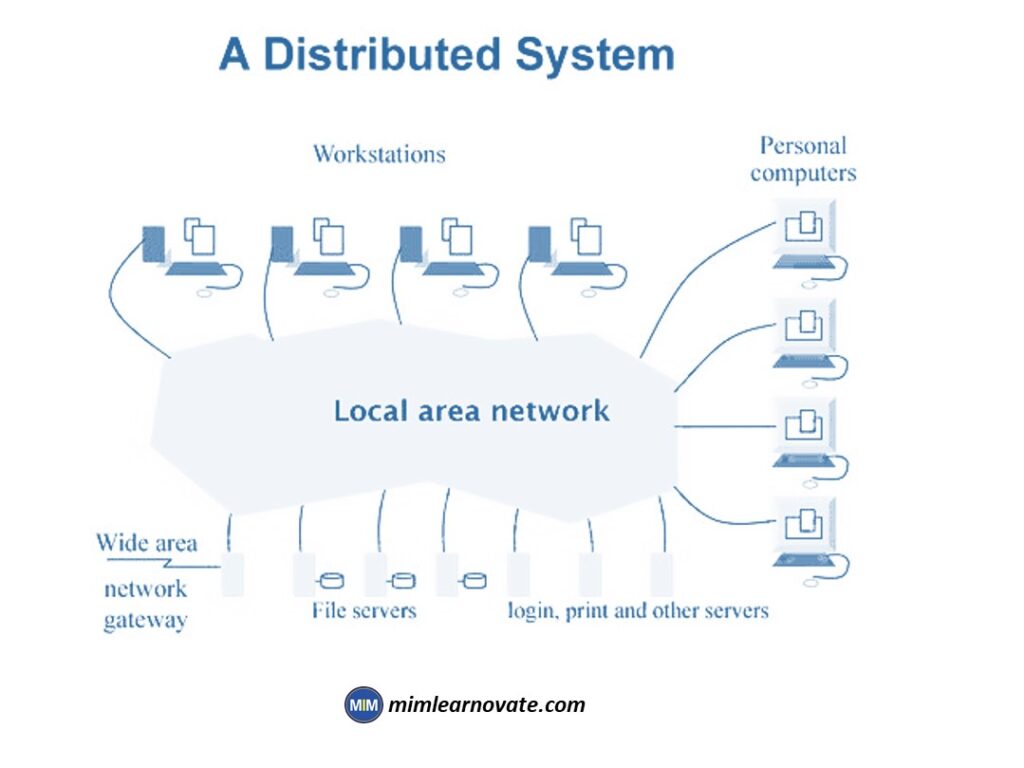
If a distributed computer system is effectively designed, it will work as a single system rather than a collection of separate computers. One result is given to the user by the system after each computer in such a network addresses its part of the overall computing requirement.
The success of distributed computing depends on the coordination of the various computers in this network.
Let’s examine one example of a distributed system to understand how it works. Think about the Google Web Server as an example. When Internet users perform a Google search, they perceive the search engine as one system.
The Google Web Server, on the other hand, is a distributed computing system that runs on a number of computers in the background. The user sees the search results with no observable lag since it sends the data processing task to a server in the appropriate location.
Below are the further examples of distributed computing systems.
- World Wide Web (WWW)
- Hadoop’s Distributed File System (HDFS)
- ATM networks
How Distributed Systems Work?
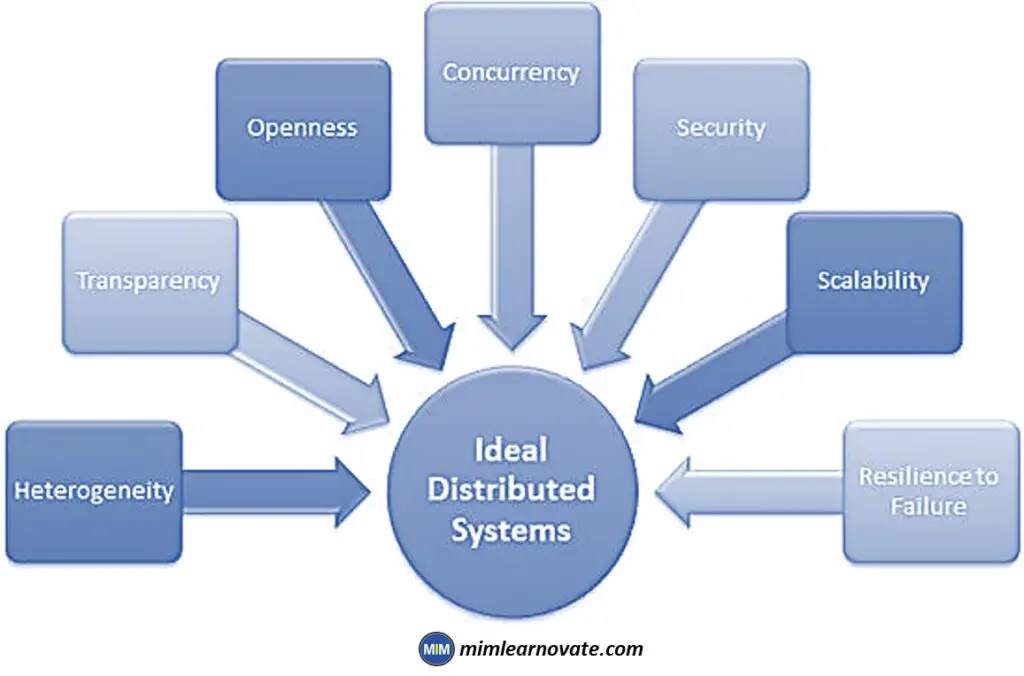
The following are the distributed computing’s most crucial features:
- Transparency: How easy it is for one node in the system to locate and communicate to other nodes.
- Resource sharing: Sharing of resources, including shared hardware, software, and data.
- Scalability: How the computing and processing power increases when spread across a large number of devices.
- Openness: How openly is the software intended to be developed and distributed?
- Concurrency: Multiple machines can perform the same function at the same time
- Fault tolerance: How fast and easily can faults in certain system parts be found and recovered?
Modern distributed systems have evolved to incorporate independent processes that may run on the same physical computer but communicate through exchanging message.
Examples of Distributed Systems Networks
When ethernet was developed and LANs (local area networks) were established in the 1970s, this is when the first distributed system was demonstrated.
A local IP address would allow computers to communicate with one another for the first time. Peer-to-peer networks developed, and the biggest, most prominent example of distributed systems is still e-mail, which led to the development of the Internet as we know it today.
Distributed systems have transitioned from “LAN” to “Internet” based when the internet transitioned from IPv4 to IPv6.
Distributed artificial intelligence
In order to learn from and handle extremely huge data sets using several agents, distributed artificial intelligence makes advantage of parallel processing and large-scale computing capacity.
Real-time distributed systems
Real-time systems that are distributed locally and worldwide are used in many different industries. Flight control systems are used by airlines, Uber and Lyft employ dispatch systems, factories use automation control systems, and logistics and e-commerce businesses use real-time tracking systems.
Parallel Processing
Previously, parallel computing and distributed systems were different. The main goal of parallel computing was to figure out how to run the same software on several threads or processors simultaneously. Separate machines with their own CPUs and memory were referred to as distributed systems. Modern operating systems, processors, and cloud services have expanded the definition of distributed computing to include parallel processing.
Distributed Database Systems
A database that is spread across several servers or actual locations is referred to as a distributed database. The data may be duplicated within a system or replicated across systems.
A distributed database is used by the majority of widely used applications, and these programs must be aware of the homogeneous or heterogeneous nature of the distributed database system.
A homogeneous distributed database is one in which the database management system and data model are same across all systems. By adding new nodes and locations, they are simpler to manage and scale in terms of performance.
Multiple data models and various database management systems are supported by heterogeneous distributed databases. Usually occurring as a result of the fusion of applications and systems, gateways are used to translate data across nodes.
Telecommunication networks
Distributed networks include cellular and telephone networks, for instance. Telephone networks have existed for more than a century and were the first peer-to-peer network.
Base stations are physically dispersed into regions known as cells in cellular networks, which are distributed networks. As voice over IP (VOIP) telephone networks have developed, their distributed network complexity has also increased.
Types of Distributed System Architectures
Distributed applications and processes often employ one of the four types of distributed system architectures listed below:
Client-server
Initially, distributed systems architecture consisted of a server as a shared resource, such as a printer, database, or web server.
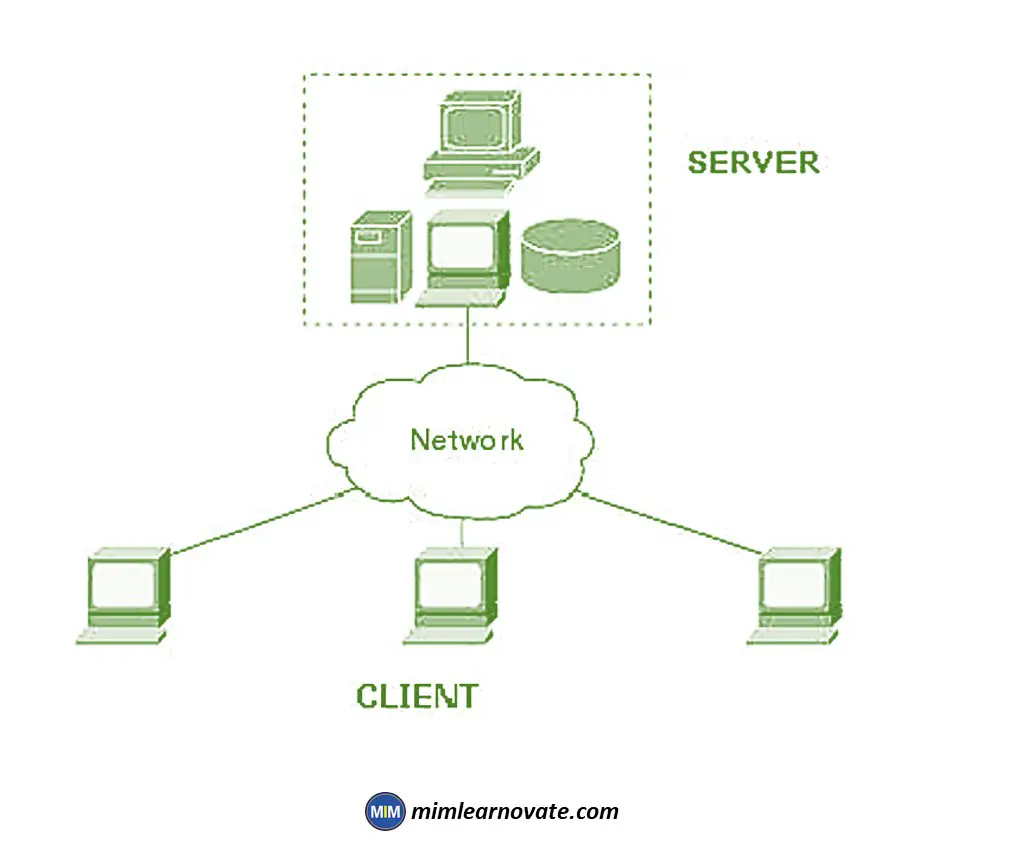
It had numerous clients (for instance, people using computers) that made decisions about whether to access shared resources, how to use and display them, how to update data, and how to communicate it back to the server.
Example of Client-server
Code repositories such as git are good example of where the intelligence is placed on the developers committing changes to the code.
Peer-to-peer
In this architecture, there are no centralized or dedicated machines that handle the heavy lifting and intelligent tasks. Each of the involved machines can play either a client or a server role, and all decision-making and duties are distributed among them.

Example of Peer-to-peer
A great example of this is the blockchain.
Three-tier
In this architecture, the middle tier handles processing and decision-making, so the clients no longer need to be intelligent. This is where the majority of the initial web applications fit.

It is possible to think of the middle tier as an agent that takes requests from clients, some of which may be stateless, processes the information, and then sends it to the servers.
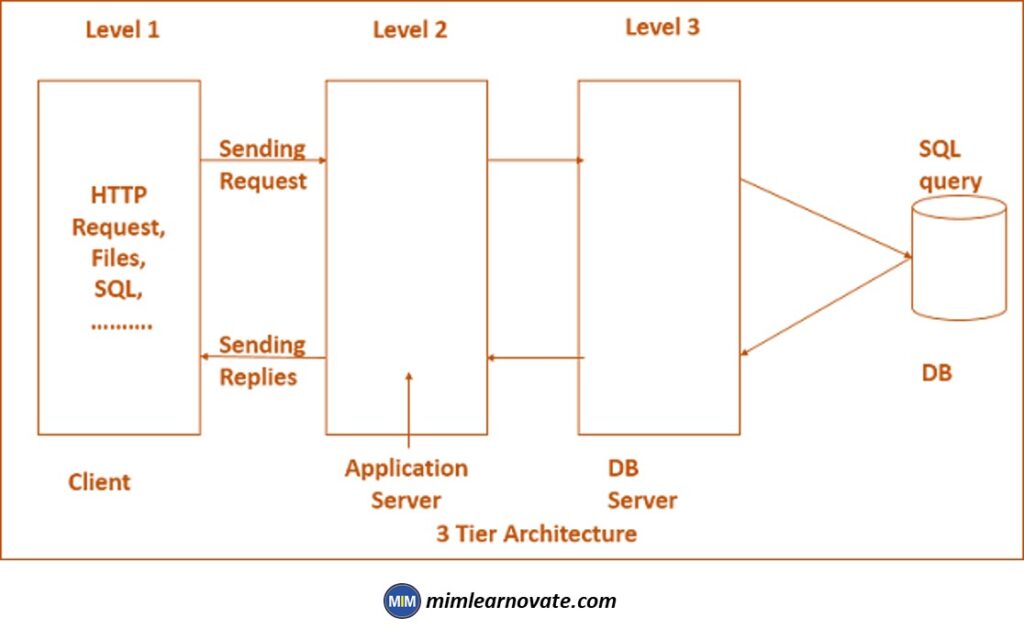
Multi-tier
N-tier or multi-tier system designs were first made possible by enterprise web services. This made application servers, which house the business logic and communicate with both the data layers and presentation tiers, more widely used.
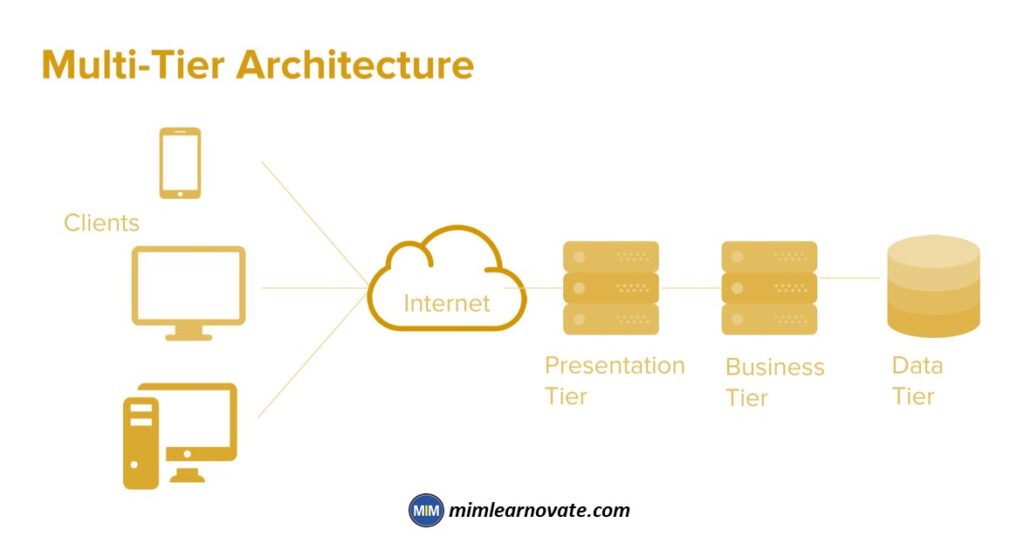
Building a Distributed Computer Solution
Here are the steps needed to build a distributed computer solution:
1. Conduct due diligence
You should first properly assess if you are developing a distributed computer system to meet your needs. A project manager (PM), an IT architect, and business analysts must first be hired.
This due diligence is crucial since, despite its benefits, a distributed computer system cannot resolve all business issues. Utilising a distributed computer system has some drawbacks, which you should take into account while performing your due diligence.
These drawbacks include the following:
- Although a distributed computer system reduces costs in the long run, developing and constructing one is expensive initially.
- A distributed computer system’s construction is complicated. Such systems are challenging to conceptualize, develop, construct, and maintain.
- Sensitive data is handled by businesses, and securing this in a distributed computer system is challenging.
2. Select a development approach
Any initiative to create a distributed computer system is significant because it represents a change in the way the organization will go on with managing its IT resources. These initiatives frequently have clear requirements.
If you intend to implement such a system within your company, be ready for thorough reviews by senior management. Such reviews after key phases will aid in mitigating project delivery risks.
Plan ahead for the following stages:
- Analysis of the requirements
- Design
- Development
- Testing
- Deployment
3. Gather, analyze, and baseline the project requirements
The business stakeholders must provide the PM, IT architect, and business analysts with the business requirements. They must first analyze the feedback from the stakeholders before producing the requirements documentation.
The requirements documents may be subjected to many reviews. Since ambiguous and changing requirements present difficulties for software development projects, it is crucial to officially baseline the requirements.
4. Establish a project team
The remaining team members must now be hired in order to fill the following positions:
- An information security architect
- DevOps engineers
- A data modeler
- Testers
- A database administrator (DBA)
- Web developers with Node.js skills
- A cloud architect
- UI designers
If you are thinking about hiring freelancers to fill these jobs, it is suggested that you hire a team of experts in the field instead. This kind of complex project needs a development team made up of experts in the field.
5. Choose the right cloud infrastructure provider
It is hard enough to build a distributed computer system, so you should help yourself as much as you can. Searching for the ideal managed cloud services provider is one technique to assist oneself. You are now relieved of the difficult task of managing the IT infrastructure.
As a top managed cloud services provider, it is advisable to use Amazon Web Services (AWS). AWS has strong cloud capabilities, and its Infrastructure-as-a-Service (IaaS) offering, Amazon Elastic Compute Cloud (EC2), is well known.
benefits of Amazon Web Services (AWS)
AWS has a number of benefits, for example:
- AWS offers a wide variety of services and makes scaling up simple.
- Due to its administration panel, AWS is simple to use and easy to sign up for.
- AWS has a strong infrastructure and a global presence, which lower latency and guarantee high availability.
- Its billing plans are flexible and simple to understand.
6. Choosing the appropriate databases and data modelling
Data modelling is a crucial next step, and you also need to choose the best database options for your proposed distributed computer system.
The following can be created as part of data modelling:
- Conceptual data models
- Physical data models (PDMs)
- Logical data models (LDMs)
Your database selection would be influenced by the requirements of your company.
MySQL is a great choice if a SQL database is required. If you require a NoSQL database, MongoDB is an ideal choice.
7. Securing your distributed system application
Almost every day, we read articles concerning sensitive data disclosure, identity theft, and data breaches. Due to data breaches, many firms had to pay fines, and their customers also had to deal with the consequences.
As a result, it’s critical to reduce the major application security threats.
There are numerous such risks, including:
- Ineffective authentication
- Incorrect implementation of identity and access management
- Inadequate security configuration
- XML external entities (XXE)
- Exposure of sensitive data
- Injection
- XSS (cross-site scripting)
- Using outdated software with known vulnerabilities
8. Building APIs
Consider creating application programming interfaces (APIs) that clients in the proposed distributed computer system can use.
benefits of APIs
APIs offer a number of benefits, such as:
- With APIs, information and service delivery is made simpler.
- APIs allow for automation, integration, and increased productivity.
REST (Representational State Transfer) and GraphQL (Graph Query Language) are two current techniques for creating and using APIs.
REST (Representational State Transfer)
In comparison to older API protocols like SOAP, RPC, CORBA, etc., REST offers substantial improvements. These earlier protocols were very rigid, so developers couldn’t add the needed flexibility to how clients and servers communicate to each other.
RESTful architecture makes use of HTTP and typical CRUD verbs such as GET, PUT, POST, and so on, allowing for much greater flexibility. It has become the standard for designing and consuming APIs.
Hire expert developers for your next project
However, under the RESTful architecture, everything revolves around the API endpoints. Even if an application only requires one field from an API endpoint, the complete endpoint must still be retrieved. We refer to it as “over-fetching”.
What happens if the application requires more information than the endpoint can provide? In such a scenario, multiple API calls are required. This is referred to as “Under-fetching”. This inefficiency has a substantial effect as the number of APIs and distributed applications accessing APIs increased significantly.
When using REST APIs, you must align the front-end views with the API endpoints. You will also need to update the back end if you choose to alter the front end.
GraphQL (Graph Query Language)
The query language in GraphQL solves these problems. Using GraphQL, developers may specify the precise fields they need, eliminating the problems associated with over- and under-fetching. Additionally, the tight coupling between the front-end and back-end is eliminated by GraphQL’s flexibility.
This doesn’t prevent you from using REST since it is still a strong and popular API architecture. Before selecting a decision, you should carefully consider your requirements.
9. Manage the caching of a distributed system architecture
A distributed computer system performs best when caching is properly managed. Your IT architect should provide a good caching strategy, for example, by allowing the application to use the user’s browser cache.
10. Web app development, testing, and deployment
You should create the web application in the suggested distributed computing system using Node.js. Popular open-source runtime environment Node.js is a great choice for developing scalable and effective web applications.
The right DevOps tools must be used when testing and delivering the app.
Pros and Cons of Distributed Systems
| Pros | Cons |
| ✔Unlimited Horizontal Scaling ✔Fault Tolerance ✔Low Latency ✔Cost-effective hardware use ✔Built-in redundancy ✔Higher degree of scalability ✔Improved performance ✔Task distribution | ❌Complexity ❌Difficulty in Data Integration ❌Network and Communication Failure ❌Management Overhead |

Benefits of Distributed Systems:
A distributed system’s main objective is to support applications’ high performance, scalability, and availability.
Major advantages consist of:
- Unlimited Horizontal Scaling: whenever needed, additional machines can be added.
- Fault Tolerance: If one server or data center fails, the service can still be provided to users.
- Low Latency: By having devices that are physically closer to users, the time it takes to service users will be shortened.
- Cost-effective hardware use: The component computers are used more frequently as the workload increases. Naturally, this results in a better price/performant ratio.
- Built-in redundancy: A distributed computer system consists of numerous component computers. This enhances redundancy and fault tolerance, making such systems more resilient to hardware or software failures.
- Higher degree of scalability: Because distributed computer systems may scale horizontally, you can gradually increase processing power and storage capacity.
- Improved performance: Distributed computer systems make use of multiple nodes to provide greater computing power and storage capacity.
- Task distribution: A well-designed distributed computer system will efficiently distribute tasks.
Disadvantages of Distributed Systems:
Complexity: Trade-offs exist in every engineering decision. The major drawback of distributed systems is complexity.
More devices, messages, and data are being transferred between more parties, which causes problems with:
- Data Consistency & Integration: It can be difficult to synchronize changes to data and application states in a distributed system, especially when nodes are starting, halting, or failing.
- Network and Communication Failure: Messages may not reach the appropriate nodes or may arrive in the wrong order, resulting in a communication and functionality breakdown.
- Management Overhead: To get visibility into the performance and faults of distributed systems, more intelligence, monitoring, logging, and load balancing functions must be added.
Other articles
Please read through some of our other articles with examples and explanations if you’d like to learn more.
Tools
- QuillBot
- Paraphraser.io
- Imagestotext.io
- Websites to Read Books for Free
- Tools to Convert PNG Image to Excel
- Detect AI-Generated Text using ZeroGPT and Transform It using Quillbot
- How is QuillBot used in Academic Writing?
- Tools for Presentations
- AI Tools for Citation Management
- Improve your Writing with QuillBot and ChatGPT
- Tools Transforming Knowledge Management
- Plagiarism Checkers Online
- Information Management Software
- Tools for Information Management
- Software Tools for Writing Thesis
- OpenAI WordPress Plugin
- TTS Voiceover
- Backend Automation Testing Tools
- AI Tools for Academic Research
Tech Hacks
Technology
- Types of software
- Firmware and Software
- WSN and IoT
- Flash Drive Vs Pen Drive
- Type A, B and C USB Cable
- Neuralink
- ReactJS
- Software Development Life Cycle Vs Software Testing Life Cycle
- Software Development Team vs Freelancer
- Quorum vs Hyperledger Fabric vs R3 Corda
- ChatGPT vs. Google Bard
- Quantum Apocalypse
- Synergy vs. KVM Switches
- eSourcing and eProcurement
- eProcurement and Traditional Procurement
- Over the Top and Video On Demand
- HDMI over IP vs HDBaseT
- Display Stream Compression
- Top Internet of Things Journals
- Supervised Learning vs. Unsupervised Learning
- Video Upscaling and Video Downscaling
- How To Build a Distributed System
- How to Get Into Data Science From a Non-Technical Background?
- How To Build Ethereum Mining Rig?
- How AI is Helpful For Marketers
- AI Chatbots Can Identify Trading Patterns
ChatGPT
- Paraphrase Text
- PowerPoint Slides
- Learn Languages
- Write Code in Python
- Write Literature Review
- Document Review
- Job Interview Preparation
- Prompts For Students
- Write Cover Letter
- Write Resume
- Write Code
- Job Applications
- Write SQL Queries
- Write Excel Formulas
- Academic Writing
- Translate Text
- Keyword Research
- Business Idea Generation
- Business Entrepreneur
- Use ChatGPT on WhatsApp
- Virtual Research Assistant
- Meta-Analysis in Research
- Large Documents
- Hypothesis Development
- Share ChatGPT Responses
- Text Analysis
- Upload PDF on ChatGPT
- Books ChatGPT