

There are two main methods used in machine learning and artificial intelligence (AI): supervised learning and unsupervised learning.
In this post, we’ll examine the key concepts of the data science approaches that is supervised learning and unsupervised learning.
The world is becoming “smarter” every day, and businesses are adopting machine learning algorithms more and more to streamline processes in order to meet consumer expectations. They are being used in end-user devices, such as face recognition for smartphone unlocking, or for identifying credit card fraud, such as by setting off alarms for out of the ordinary purchases.
Supervised Learning
The use of labelled datasets distinguishes the machine learning approach known as “supervised learning.” These datasets are intended to “supervise” or “train” algorithms to correctly classify data or forecast outcomes. Labelled inputs and outputs allow the model to monitor its precision and improve over time.
Example of Supervised learning
A supervised learning model, for instance, can forecast how long your commute will be based on the time of day, the weather, and other factors. But first, you’ll need to teach it that driving time increases in rainy weather.
When using data mining, supervised learning can be divided into two types:
- Classification
- Regression
Classification
Using an algorithm, classification problems efficiently categorize test data into distinct groups, such as separating apples from oranges.
Use of supervised learning algorithms
Alternately, supervised learning algorithms can be applied in the real world to categorize spam in a distinct folder from your email.
Types of classification algorithms
Common classification algorithms include decision trees, support vector machines, random forest, and linear classifiers.
regression
Another supervised learning technique that employs an algorithm to comprehend the link between dependent and independent variables is regression.
Regression models are useful for making predictions about numbers based on several data points, such as sales revenue projections for a particular business.
Types of regression algorithms
Polynomial regression, logistic regression, and linear regression are some common regression algorithms.
Unsupervised learning
Machine learning algorithms are used in unsupervised learning to analyze and group unlabeled data sets. These algorithms are referred to as “unsupervised” since they identify hidden patterns in data without the assistance of a person.
Example of Unsupervised learning
An unsupervised learning model, for instance, can determine that online buyers frequently buy bundles of products at once. However, a data analyst would need to validate that it makes sense for a recommendation engine to group baby apparel with a selection of diapers, applesauce, and sippy cups.
Use of Unsupervised learning algorithms
Unsupervised learning models are used for:
- Association
- Clustering
- Dimensionality reduction
Association
Association employs different rules for finding relationships between variables in a given dataset. The “Customers Who Bought This Item Also Bought” recommendation engine and market basket analysis typically employ these methods.
Clustering
Unlabeled data can be grouped using the data mining technique of clustering based on their similarities or differences.
Example of Clustering in Unsupervised learning algorithm
K-means clustering algorithms divide related data points into groups, where the K value denotes the size and granularity of the grouping. This method is useful for image compression and market segmentation.
Dimensionality reduction
Dimensionality reduction is a learning approach used when the number of features (or dimensions) in a given dataset is too high. It keeps the data integrity preserved while reducing the number of data inputs to a manageable level.
Typically, this technique is employed in the preprocessing stage of data, such as when autoencoders remove noise from visual data to enhance image quality.
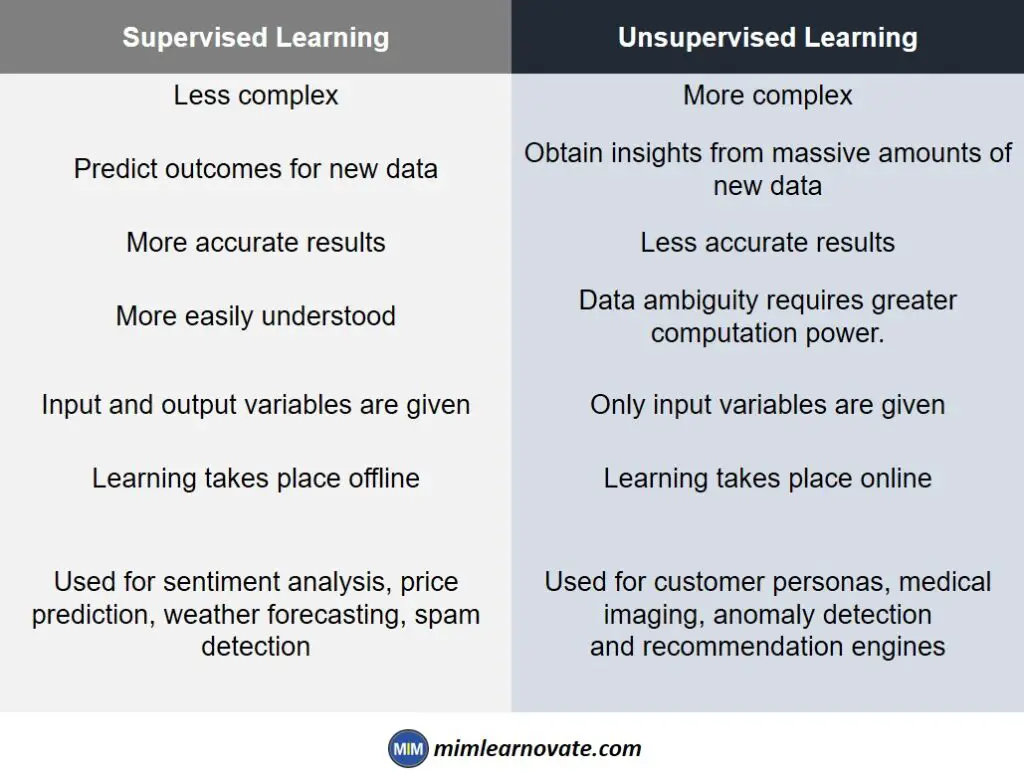
difference between supervised and unsupervised learning
- Supervised learning employs labelled input and output data, whereas an unsupervised learning system does not.
- Supervised learning models are excellent for a variety of tasks, including sentiment analysis, price prediction., weather forecasting, spam detection. Unsupervised learning, on the other hand, is ideal for customer personas, medical imaging, anomaly detection and recommendation engines.
- In supervised learning, the algorithm “learns” by iteratively generating predictions on the data and adjusting for the proper answer. Unsupervised learning models are more likely to be inaccurate than supervised learning models, but supervised learning models need upfront human intervention to label the data correctly.
- Supervised learning is a simple machine learning method that is commonly computed using tools like R or Python. You need powerful tools for unsupervised learning in order to handle huge amounts of unclassified data. Unsupervised learning models require a large training set in order to yield the desired results, making them computationally complex.
- In supervised learning, the objective is to predict outcomes for new data. The kind of outcomes you can expect are known up front. The objective of an unsupervised learning algorithm is to obtain insights from massive amounts of new data. What is different or interesting about the dataset is decided by the machine learning algorithm itself.
- The labels for the input and output variables require expertise, and the training of supervised learning models might take a long time. Unsupervised learning techniques, on the other hand, might produce radically incorrect results unless there is intervention to validate the output variables.
Supervised Learning vs Unsupervised Learning
| Supervised Learning | Unsupervised Learning |
| Less complex | More complex |
| Predict outcomes for new data | Obtain insights from massive amounts of new data |
| More accurate results | Less accurate results |
| More easily understood | Data ambiguity requires greater computation power. |
| Input and output variables are given | Only input variables are given |
| Learning takes place offline | Learning takes place online |
| Used for sentiment analysis, price prediction, weather forecasting, spam detection | Used for customer personas, medical imaging, anomaly detection and recommendation engines |
Other articles
Please read through some of our other articles with examples and explanations if you’d like to learn more.
Tools
- QuillBot
- Paraphraser.io
- Imagestotext.io
- Websites to Read Books for Free
- Tools to Convert PNG Image to Excel
- Detect AI-Generated Text using ZeroGPT and Transform It using Quillbot
- How is QuillBot used in Academic Writing?
- Tools for Presentations
- AI Tools for Citation Management
- Improve your Writing with QuillBot and ChatGPT
- Tools Transforming Knowledge Management
- Plagiarism Checkers Online
- Information Management Software
- Tools for Information Management
- Software Tools for Writing Thesis
- OpenAI WordPress Plugin
- TTS Voiceover
- Backend Automation Testing Tools
- AI Tools for Academic Research
Tech Hacks
Technology
- Types of software
- Firmware and Software
- Central Processor Unit (CPU)
- WSN and IoT
- Flash Drive Vs Pen Drive
- Type A, B and C USB Cable
- Neuralink
- ReactJS
- Software Development Life Cycle Vs Software Testing Life Cycle
- Software Development Team vs Freelancer
- Quorum vs Hyperledger Fabric vs R3 Corda
- ChatGPT vs. Google Bard
- Quantum Apocalypse
- Synergy vs. KVM Switches
- eSourcing and eProcurement
- eProcurement and Traditional Procurement
- Over the Top and Video On Demand
- HDMI over IP vs HDBaseT
- Display Stream Compression
- Top Internet of Things Journals
- Supervised Learning vs. Unsupervised Learning
- Video Upscaling and Video Downscaling
- How To Build a Distributed System
- How to Get Into Data Science From a Non-Technical Background?
- How To Build Ethereum Mining Rig?
- How AI is Helpful For Marketers
- AI Chatbots Can Identify Trading Patterns
ChatGPT
- Paraphrase Text
- PowerPoint Slides
- Learn Languages
- Write Code in Python
- Write Literature Review
- Document Review
- Job Interview Preparation
- Prompts For Students
- Write Cover Letter
- Write Resume
- Write Code
- Job Applications
- Write SQL Queries
- Write Excel Formulas
- Academic Writing
- Translate Text
- Keyword Research
- Business Idea Generation
- Business Entrepreneur
- Use ChatGPT on WhatsApp
- Virtual Research Assistant
- Meta-Analysis in Research
- Large Documents
- Hypothesis Development
- Share ChatGPT Responses
- Text Analysis
- Upload PDF on ChatGPT
- Books ChatGPT